1 Introduction
Pandemia is an individual-based stochastic pandemic simulator. It simulates and visualizes the spread of an infectious disease across multiple geographical regions. These regions might represent the countries of the world, or the administrative divisions of a single country.
The software parallelizes computation over the regions, calculating the interactions between regions on a coarser timescale than the one used to discretize the individual-based simulations within each region. The user can specify a scale factor, adjusting the number of individuals, locations, and other relevant quantities appearing in each region. Pandemia is therefore fast and scalable, able to simulate extremely large numbers of individuals, while supporting a wide range of highly adaptable features.
This software will be of use to researchers looking to assess the impact of policy in the context of a public health emergency caused by an infectious disease of humans. The disease could, for example, be a respiratory infectious disease spread by a coronavirus or an influenza virus. The emergence and re-emergence of infectious diseases threatens the health and well-being of people all over the world. Tools such as Pandemia can play a vital role in supporting pandemic preparedness and response.
This user guide presents an overview of the model and its various components.
2 World
The Pandemia simulator acts upon a World. A World consists of Regions, with each Region consisting of Agents, Locations and Activities. Each agent performs a sequence of activities, and performs these activities in particular locations. A World additionally consists of a Travel Matrix, representing how many agents travel from each region to each other region each day. Here is the simplest possible World structure:
One Region, one Activity, one Location and any number of Agents.
Here is the most complicated:
Several Regions, with each Region consisting of several Activities, any number of Locations and any number of Agents, with a Travel Matrix describing the mixing between regions.
2.1 Agents
An individual human is referred to in the model as an Agent. Each agent is described by their age, a weekly routine of activities, locations at which the agent might perform these activities, and weights indicating the probabilities of these locations being chosen by that agent.
2.2 Locations
A Location represents, for example, an area of land or a building, such as a house, restaurant, shop or school classroom. A location is described by its type, for example House or Hospital, and a pair of spatial coordinates.
2.3 Activities
An Activity is something an agent does, for example cooking, driving to work, or shopping. Activities are simply labels, with no additional structure.
2.4 Regions
A Region represents, for example, a country or an administrative division of a country. A region consists of a set of activities, a set of agents, and a set of locations.
2.5 World Factory
A World is built by a World Factory. Different worlds can be obtained either by changing the configuration of a world factory, or by using a different world factory entirely.
2.6 Vectorization
Once a World has been built, it is then converted into a Vector World. This is done by converting each Region into a Vector Region. A Vector Region is a vectorized version of a Region, in which data is formatted as arrays of integers and floats, as opposed to Python lists and dictionaries. This facilitates interface with libraries of functions written in C.
3 Simulator
The Pandemia Simulator is the object that performs the pandemic simulation. Global parameters include the aforementioned scale factor, a random seed and the option of whether or not to parallelize the computation. The Simulator consists of a Clock, which represents time, a World and a number of Components and Reporters.
3.1 Clock
The Clock keeps track of time. It is an iterator that counts forward in time by one day, with each day being subdivided into ticks. Some components update each tick, while others update only each day. Interactions between regions, for example, are calculated at the beginning of each day.
3.2 World
The World is an object of the type described in the previous section, consisting of regions, with the regions consisting of agents, locations and activities.
3.3 Components
The model features of a number of Components:
Movement
Health
Hospitalization
Testing and Contact Tracing
Vaccination
Seasonality
Travel
Pandemia provides a default model for each component, and a void model in which the component is inactive. The details of these default models will be described in subsequent sections.
3.4 Reporters
A Reporter collects data from the simulation for output and visualization. The simulator contains a message bus that broadcasts data labelled by topic, for example on new infections and deaths, while reporters subscribed to these topics collect the data and organize it. Some reporters save CSV files, tabulating infections by country, strain and date. Others save PNG files, plotting infections and deaths. There are also reporters that provide real time visualization of the simulation, using shapefiles or grid data supplied for the regions in question. All relevant parameters, including the filepaths of the output data, are specified by the user in the configuration file.
3.5 Simulator Factory
The Simulator Factory builds the simulator. The first step is to build the clock and world. Having done so, the simulator factory can then be saved and reloaded. It is therefore not necessary to build a world every time a simulation is run. This is useful since building a world might be computationally intensive. The next step is to initialize the components and finally the reporters.
3.6 Run
Once the simulator has been built, it can then be run! The main Pandemia loop looks approximately as follows:

Note that some components update each day, while others update each tick. At the beginning of each day, Pandemia decides who is travelling from each region to each other region, and infects these travellers based on the average infectiousness of their destination region. These travellers are then set aside for the remainder of the day. Pandemia then loops over the regions, performing independent agent-based simulations. Since for the remainder of the day these simulations are independent, the loop over the regions can be parallelized. In this way, Pandemia is both fast and scalable. On a laptop computer, using 15 CPUs and 24GB of RAM, Pandemia has been able to perform a 100 day simulation with 24 ticks per day, of over 100 million agents, in under 1.5 hours.
4 Policy Maker
The Policy Maker component allows the user to specify a Policy, consisting of interventions. A policy is encoded by arrays of integers and floats, indicating the availability or strength of various interventions in each region each day. Currently supported interventions include:
Lockdown
Border Closure
Vaccination
Testing and Contact Tracing
Quarantine
Face Masks
The interventions are implemented inside the relevant components. For example, a lockdown is implemented within the movement component.
5 Movement
In the default movement model, each agent performs a sequence of activities and performs these activities at particular locations. The default movement model requires a world featuring a home location for each agent.
Recall that, during the building of the world, each agent is assigned a weekly routine consisting of a sequence of activities. It is assumed that these routines start on a Sunday. For example, suppose in a given region there are three activities, Home, Work and School, and that we wish to specify the routine of agents with an 8 hour time resolution. Then one weekly routine could be:
[Home, Home, Home, Home, Work, Home, Home, Work, Home, Home, Work, Home, Home, Work, Home, Home, Work, Home, Home, Home, Home]
representing a typical working week, while another weekly routine could be:
[Home, Home, Home, Home, School, Home, Home, School, Home, Home, School, Home, Home, School, Home, Home, School, Home, Home, Home, Home]
representing a typical school week.
Recall also, that during the building of the world, each agent is assigned a weighted set of locations for each activity. For example, suppose in a given region there are two activities, Home and Other. Then, a given agent might be assigned a single location for the activity Home, with weight \(1.0\), and several other locations for the activity Other, with weights chosen according to the distance from home, so that locations further from home are less likely to be visited.
In the default movement model, whenever an agent switches from one activity to another, the agent randomly selects a new location from the corresponding set of locations, using the specified weights, at which they will then perform this new activity. Upon changing activity, agents may also put on or take off a face mask, depending on the activity and the current policy on face masks, as specified by the Configuration and Policy Maker. If the change of location is prohibited by a policy intervention, for example a lockdown, then the choice of agent is overridden and they are instead directed to their home location. In particular, each agent must for the default movement model be assigned a home location.
6 Health
Infectious disease models typically represent health using discrete states. In such a compartmental model, the population is partitioned into subsets, labelled Susceptible, Infected, Recovered and Dead. These compartments can then be subdivided, and new compartments added, to produce increasingly complicated models. This approach runs into difficulties once partial immunity is introduced, since the compartmental label Recovered then becomes ambiguous. It runs into further difficulties once multiple strains of the pathogen are introduced, since then the label Susceptible becomes ambiguous.
Pandemia therefore dispenses with the compartmental framework altogether, taking an entirely new approach to modelling individual health. In the default health model, the health of an individual is described by five attributes:
Strain
Disease
Infectiousness
Immunity (outer layer)
Immunity (inner layers)
The immune system is represented using layers, with the outer layer determining whether or not an infection is blocked, and the inner layers determining the outcome for infections that are not blocked. A key innovation of Pandemia is that, for each individual, these five attributes are stored as functions. The value of an attribute at time \(\texttt{t}\) is given by evaluating the corresponding function at time \(\texttt{t}\). During a simulation, the following variables store the values of these functions at the current time:
current_straincurrent_diseasecurrent_infectiousnesscurrent_sigma_immunity_failurecurrent_rho_immunity_failure
The prefix sigma_ refers to the outer layer of the immune
system, while the prefix rho_ refers to the inner layers.
6.1 Strain
For agent \(\texttt{n}\), the variable
indicates whether or not agent \(\texttt{n}\) is infected, and if so with which strain. The variable is an integer, taking values in the range
where \(\texttt{S}\) denotes the number of strains. If the agent is not infected, then
We assume that agents can only be infected with one strain at a time.
6.2 Disease
For agent \(\texttt{n}\), the variable
indicates the extent to which agent \(\texttt{n}\) is diseased. The variable is a float, taking values in the range \(\texttt{[0,1]}.\) If the agent has no disease, then
If the agent is dead, then
Values close to \(\texttt{1}\) represent severe disease, values close to \(\texttt{0}\) represent mild disease. Values above a threshold represent symptomatic disease, values below the threshold represent asymptomatic disease.
6.3 Infectiousness
For agent \(\texttt{n}\), the variable
indicates the extent to which agent \(\texttt{n}\) is infectious. The variable is a float, taking non-negative values. If the agent is infected but not infectious, then
If the agent is infected, then increasing the value of this variable increases the probability that the agent transmits strain \(\texttt{current_strain[n]}\) to other agents.
6.4 Immunity (Outer Layer)
For agent \(\texttt{n}\) and strain \(\texttt{s}\), the variable
represents the probability that the immune system of agent \(\texttt{n}\) fails to prevent an infection when exposed to strain \(\texttt{s}\). Being a probability, this variable is therefore a float taking values in the range \(\texttt{[0,1]}.\) Since this variable stores a failure probability, values closer to \(\texttt{0}\) represent higher levels of protection.
6.5 Immunity (Inner Layers)
If sigma immunity fails, then the pathogen makes it past the outer layer of defence and an infection occurs. The pathogen now confronts a number of internal layers. Each layer has a probability of failing to stop the pathogen, with the outcome of the infection getting progressively worse the deeper the pathogen penetrates. This binary tree structure allows the user to parametrize, for example, the efficacy of a vaccine against symptomatic disease, severe disease and death. If the pathogen passes through all but the last internal layer, which is impenetrable, then the agent experiences the worst possible outcome.
For example, suppose the model is configured in such a way that there are two internal layers. Then, for a given agent, infected with a given strain, there are two possible outcomes. If the first internal layer fails to stop the pathogen, then the outcome will be the latter of the two outcomes. If the first internal layer is successful, then the outcome will be the former of the two outcomes. These two outcomes could, for example, be configured to represent recovery and death, respectively.
More generally, suppose the model is configured in such a way that there are \(\texttt{R}\) internal layers, and therefore \(\texttt{R}\) possible outcomes. Then, for agent \(\texttt{n}\) and strain \(\texttt{s}\), the variable
gives a vector of probabilities, of length \(\texttt{R}\), corresponding to the failure probabilities of each layer. If a pathogen makes it past layer \(\texttt{r}\), then it moves on to face layer \(\texttt{r+1}\), else the agent gets outcome \(\texttt{r}\). Since the last layer is impenetrable, the final entry in this vector is always equal to \(\texttt{0}\), meaning that the last layer never fails to stop the pathogen.
The sampling of this binary tree structure occurs immediately after infection.
While sigma immunity determines whether or not an infection occurs, with rho immunity determining the outcome of that infection, to understand the outcomes themselves we must discuss the \(\texttt{health_presets}\).
6.6 Presets and Updates
The default response to an infection is determined for each agent, for each strain, during the initialization of the health component, before the start of the simulation. In particular, if an agent has been assigned the preset response \(\texttt{p}\) from the set of possible presets \(\texttt{health_presets}\), then the object \(\texttt{p[r]}\) contains data which determine updates, for each of the five health attributes described above, corresponding to outcome \(\texttt{r}\).
For example, suppose that our model features two strains and two internal layers. Then the object \(\texttt{p[r]}\) may be as follows:

The numbers in these arrays encode step functions. For example, the pair of arrays
encodes the step function \(f\) given by
Suppose in the above example that agent \(\texttt{n}\) has just been infected with strain \(\texttt{0}\), and that the infection has resulted in outcome \(\texttt{r}\), with \(\texttt{p[r]}\) as above. Then the variable \(\texttt{current_strain[n]}\) will take the value \(\texttt{0}\) for the next \(\texttt{5}\) days, after which it will return to the value \(\texttt{-1}\), indicating that the agent is no longer infected. The variable \(\texttt{current_disease[n]}\) will take the value \(\texttt{0.2}\) for the next \(\texttt{5}\) days, after which it will return to the value \(\texttt{0.0}\), indicating that the agent has recovered. The variable \(\texttt{current_infectiousness[n]}\) will take the value \(\texttt{0.0025}\) for the next \(\texttt{3}\) days, followed by \(\texttt{0.0075}\) for \(\texttt{2}\) days, after which it will return to the value \(\texttt{0.0}\), indicating that the agent is no longer infectious.
Updates to the sigma and rho immunity variables are more complicated. The immunity variables are updated via the operation of function multiplication. Recall that the immunity functions store probabilities of failure, so the product of such functions give the probabilities of failure for overlapping immune responses, assuming independence.
Suppose in the above example that agent \(\texttt{n}\) has no immunity against either strain prior to infection. Assume that the infection with strain \(\texttt{0}\) occurred at time \(\texttt{t}\). Then, after updating their immunity functions, the component of their sigma immunity function corresponding to strain \(\texttt{0}\) will be given by the step function
while the component corresponding to strain \(\texttt{1}\) will be given by
In particular, for 25 days following the end of their infection, the probability that their immune system fails to protect against another infection by strain \(\texttt{0}\) is improved from \(\texttt{1.0}\) to \(\texttt{0.25}\), after which it returns to \(\texttt{1.0}\), representing a loss of immunity. The probability that their immune system fails to protect against an infection by strain \(\texttt{0}\) is improved from \(\texttt{1.0}\) to \(\texttt{0.5}\), after which it returns to \(\texttt{1.0}\), representing a loss of cross immunity.
Suppose now that at time \(\texttt{t + 10}\) agent \(\texttt{n}\) is again infected by strain \(\texttt{0}\). Then between times \(\texttt{t + 10}\) and \(\texttt{t + 15}\), the three variables describing their current strain, disease and infectiousness will be updated as before. But the component of their sigma immunity function corresponding to strain \(\texttt{0}\) will now be subject to appropriate multiplication, after which it will be given by the step function
In particular, between times \(\texttt{t + 15}\) and \(\texttt{t + 30}\) there are overlapping immunity responses, so that in order for a third infection to occur by strain \(\texttt{0}\), the pathogen must overcome the immune response generated by the first infection and the immune response generated by the second infection. Our assumption is that these events are independent, hence the multiplication of probabilities.
Updates to rho immunity are similar, except that these functions are now vector-valued, these vectors corresponding to the failure probabilities for each internal layer, meaning that the functions must be multiplied element-wise.
For a preset \(\texttt{p}\) and outcome \(\texttt{r}\), while the components of \(\texttt{p[r]}\) corresponding to strain, disease and infectiousness each contain precisely \(\texttt{S}\) functions, where \(\texttt{S}\) is the number of strains, the components corresponding to rho and sigma immunity are containing precisely \(\texttt{S} \times \texttt{S}\) functions, the additional dimension accounting for cross-immunity as in the above example.
6.7 Transmission
For a location \(l\) in region \(i\), we define:
where \(m \in l\) means all agents \(m\) currently in location \(l\), with
Here
\(\omega_m\) is the current face mask multiplier associated to agent \(m\), which takes the value \(1\) if they are not wearing a face mask, and some number smaller that \(1\) if they are;
\(\nu_m\) is the current infectiousness of agent \(m\);
\(\mu\) is a multiplier depending on the region \(i\), reflecting for example seasonal changes in transmission that act on the regional level;
\(\lambda\) is a multiplier depending on the location \(l\), reflecting the fact that some types of location might be less conducive to transmission than others;
\(\beta\) is a control coefficient depending on the strain \(s_m\) that agent \(m\) is currently infected with, if any.
For each susceptible agent \(n\) in location \(l\), with current face mask multiplier \(\omega_n\), the probability that they are exposed at this time is then assumed to be \(\omega_n p_l\). If such an agent is exposed, then to determine which strain they are exposed to, we assume the expression
gives the probability that they are exposed to strain \(s\). Given this exposure, the probability that they are actually infected with strain \(s\) is then \(\sigma_{ns}\), the current sigma immunity of agent \(n\) against strain \(s\). The outcome of this infection is then determined by the rho immunity of the agent, according the procedure outlined in the previous subsections.
6.8 SIR Rescaling
If the option \(\texttt{sir_rescaling}\) is set to \(\texttt{True}\), then transmission probabilities are rescaled in such a way that approximates the homogeneous mixing of standard compartmental models. In particular, the \(\texttt{sir_rescaling}\) option multiplies all health model transmission probabilities by the reciprocal of the tick length, in days, divided by the number of agents in each location. Moreover, with this option activated it is also possible to implement a contact matrix, that can be used to represents differential mixing between population subgroups, for example age groups.
For example, suppose there is only one region, one location, one strain and no face masks. Suppose that \(\nu_m = 1\) if \(m\) is infected, with \(\nu_m = 0\) otherwise. Denote by \(N_{a}\) the number of people in group \(a\) and by \(h\) the step size (that is, the reciprocal of the tick length, in days). Then the \(\texttt{sir_rescaling}\) option multiplies all health model transmission probabilities by \(h / N_a\). Denoting by \(m_{ab}\) the mixing between groups \(a\) and \(b\) and by \(I_b\) the number of currently infected agents in group \(b\), for an agent \(n\) in group \(a(n)\), we have:
where \(M_{ab} := m_{ab} / N_b\) is the normalized contact matrix. This is consistent with a standard compartmental model, since the expected number of new infections in age group \(a\) at time \(t\) then satisfies the approximation
In particular, with only one population subgroup we have \(M = 1 / N\), therefore recovering the first equation
of the SIR model. With exponentially distributed recovery times, and no reinfection, we recover the remaining equations, and therefore arrive at a stochastic approximation of the SIR model. With the option \(\texttt{sir_rescaling}\) set to \(\texttt{True}\), the Pandemia default health model can be therefore viewed as a stochastic agent-based generalization of standard compartmental models.
On the other hand, with the option \(\texttt{sir_rescaling}\) set to \(\texttt{False}\), the transmission probabilities are not divided by the number of agents in each location. This means that adding susceptible agents to the location of an infected agents does not dilute the infectiousness of that agent, as it does under homogeneous mixing. For example, if Alice and Bob are riding a bus, and Bob is infectious, then with homogeneous mixing the probability that Alice is infected by Bob decreases if more susceptible people get on the bus.
For worlds with large numbers of agents per location, setting the option \(\texttt{sir_rescaling}\) to \(\texttt{True}\) may be appropriate, whereas for worlds with large numbers of locations, with typically only a few agents per location at each time, setting the option \(\texttt{sir_rescaling}\) to \(\texttt{False}\) might be preferable. The latter scenario should, typically, be more realistic.
7 Hospitalization
In the default hospitalization and death model, if a region contains at least one hospital, meaning a location of type Hospital, then agents whose current disease level is above a specified threshold, and who are about to move to a new location, are admitted to hospital instead. They remain there until their current disease level falls below the threshold, after which the agent is free to return home or move to other locations. The hospital that an agent is admitted to is chosen at random for all such locations in the region. Note that hospitalization in the default model has no impact on the disease level of an agent, only on their location. Note also that the hospitalization component updates after the movement component, meaning that hospitalization overrides self-isolation and any interventions on movement such as lockdowns.
In the default model, if a region contains at least one cemetery, then agents whose current disease level is \(\texttt{1.0}\) are considered dead and moved to a randomly selected cemetery, where they remain for the rest of the simulation.
If a region contains neither a hospital nor a cemetery, then the hospitalization and death model does nothing in that region.
8 Testing and Contact Tracing
The default testing and contact tracing model requires the default health model and a world featuring a home location for each agent. The model implements diagnostic tests, contact tracing and self-isolation. Self-isolation directs an agent to remain at home for the duration of the self-isolation period. In particular, each agent must for the default testing and contact tracing model be assigned a home location.
The policy maker component specifies how many test are available in each region each day, for each of the following three systems:
Random Testing
Symptomatic Testing
Contact Tracing
The policy maker component also specifies how many agents can have their contacts traced each day. If an agent is tested and their current infectiousness is above the test threshold, then with probability \(1 - p\) the agent tests positive, where \(p\) is the probability of a false negative.
8.1 Random Testing
In each region each day, a number of agents are tested at random. Those who test positive begin self-isolating, meaning that all new activities must be performed at their home location, for a specified number of days.
8.2 Symptomatic Testing
An agent is considered symptomatic if their current disease is above a specified threshold. If an agent is currently symptomatic, having being asymptomatic the previous day, then they are eligible for this system of testing. A number of these eligible agents are randomly selected for testing, beginning periods of self-isolation if they test positive. Eligible agents who are not selected for testing may still, with a specified probability, begin self-isolating, reflecting the possibility that even without a test result a symptomatic agent might choose to self-isolate anyway.
8.3 Contact Tracing
In the default model, a regular contact of an agent is any other agent who shares the same home location. Each day, the regular contacts of each agent testing positive are considered to be at risk, and are themselves eligible for testing, if they have not already been tested this day. From these agents at risk a subset are randomly selected for testing, with those testing positive beginning periods of self-isolation. The remaining agents at risk may each still begin self-isolating, with a specified probability.
The user might wish to expand the regular contacts to include workmates and classmates, should the user first implement a world with such features. The user is warned, however, that increasingly complex contact tracing systems can become computationally very intensive. The default model is therefore simple, but fast.
9 Vaccination
The default vaccination model requires the default health model. The model supports multiple vaccines, and for each vaccine, the configuration specifies how the rho and sigma immunity of an agent should be updated, for each strain, after receiving a dose of the vaccine. Consider, for example, the following configuration:

Here the vaccine \(\texttt{vaccine_0}\) encodes updates to rho and sigma immunity for two strains of the pathogen. The updates follow the exact same multiplicative procedure as the immunity updates resulting from an infection, as described in Section 6. The model also features age-dependent vaccine hesitancy, and a minimum time between doses. The policy maker component specifies how many doses of each vaccine are available in each region each day, for each age group, with this number of doses being administered to a randomly selected subset of all eligible and willing agents.
10 Seasonality
The seasonal effects component of the Pandemia simulator can be used to configure monthly updates to the regional transmission multipliers. The default seasonal effects model calculates a transmission multiplier for each country each month. The default value of these multipliers is \(\texttt{1.0}\), meaning no reduction in transmission. The alternative value is a float taking values in the range \(\texttt{[0,1]}\). The months during which transmission is reduced to this value are configured in a data file.
11 Travel
The travel model implements mixing between regions. It requires the default health model. At the beginning of each day, a number of uninfected agents are randomly selected to travel from each region to each other region.
The policy maker component associates to each region for each day a multiplier in the range \(\texttt{[0,1]}.\) This multiplier represents the extent to which travel out of the region is reduced by border restrictions that day, with the value \(\texttt{0}\) representing total suppression of travel out of the country. The number of agents travelling between regions \(i\) and \(j\) is therefore given by the corresponding entry in the Travel Matrix, multiplied by the border closure multiplier of region \(i\).
Travellers mix homogeneously with the entire population of the destination region. In particular, for each region \(j\), an aggregated level of infectiousness is calculated, with this resulting probability, \(p_j\), being calculated as:
where \(m \in j\) means all agents \(m\) currently in location \(j\), with
where these parameters are defined as in the default health model with
\(N_j\) the number of agents in region \(j\);
\(\tau\) is a control parameter.
For each uninfected agent \(n\) travelling to region \(j\), with current face mask multiplier \(\omega_n\), the probability that they are exposed at this time is then assumed to be \(\omega_n p_j\). If such an agent is exposed, then to determine which strain they are exposed to, we assume the expression
gives the probability that they are exposed to strain \(s\). Given this exposure, the probability that they are actually infected with strain \(s\) is then \(\sigma_{ns}\), the current sigma immunity of agent \(n\) against strain \(s\). The outcome of this infection is then determined by the rho immunity of the agent, according the procedure outlined in the section on the default health model.
The current region of an agent \(\texttt{n}\) is recorded by the variable
Agents whose current region is not their home region are considered travellers, and are ignored by other components where appropriate for the remainder of the day.
12 Examples: World Factories and Scenarios
All parameters, including the scale factor and random seed, are configured in a single file, called the Configuration. The choice of world factory is specified in the configuration. Several example world factories have been provided, in particular the homogeneous mixing example \(\texttt{Homogeneous}\) and the heterogeneous mixing example \(\texttt{Heterogeneous}\). File paths to input data are also specified in the configuration.
Example configurations and input data are collected into Scenarios.
12.1 Homogeneous Mixing
The \(\texttt{Homogeneous}\) world factory builds regions corresponding to the countries of the world, where for each region there is only one activity and one location, equivalent to the region itself. Mixing within each country is therefore homogeneous. Mixing between regions is determined using air travel data.
In this homogeneous mixing scenario, agents are not assigned homes. Consequently, movement and testing and contact tracing models are void, the associated interventions and dynamics being irrelevant to this scenario.
Using the default reporter to render prevalence within each region, the \(\texttt{Homogeneous}\) scenario can be visualized as follows:
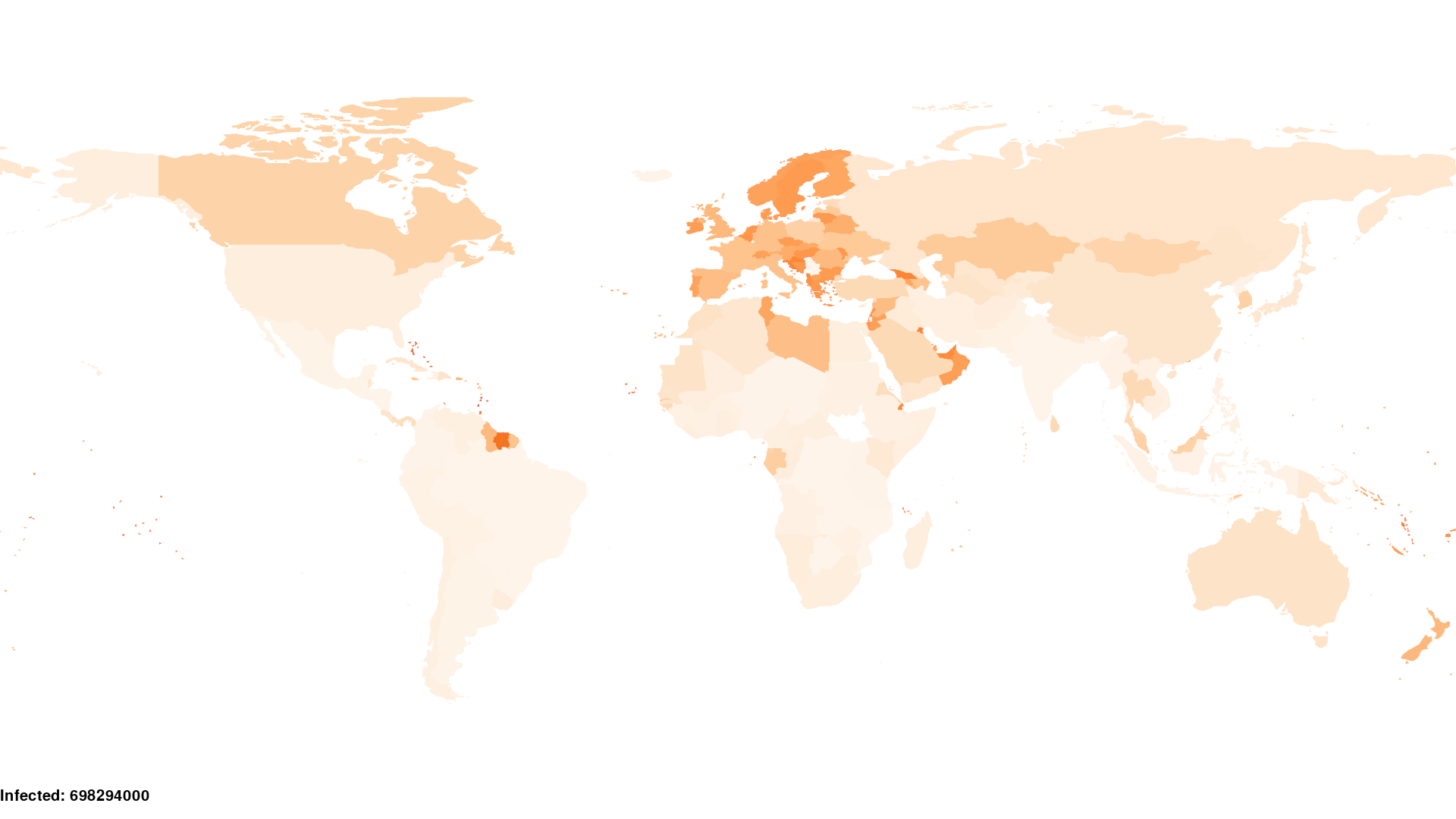
12.1.1 Input data
The input data for the \(\texttt{Homogeneous}\) scenario comes from a number of sources. The shape files come from Eurostat:
The influenza data used to configure the seasonality model come from:
Newman LP, Bhat N, Fleming JA, Neuzil KM. Global influenza seasonality to inform country-level vaccine programs: An analysis of WHO FluNet influenza surveillance data between 2011 and 2016. PLoS One. 2018 Feb 21;13(2):e0193263. doi: 10.1371/journal.pone.0193263.
Data on population size and age structure come from the UN:
United Nations, Department of Economic and Social Affairs, Population Division (2022). World Population Prospects 2022, Online Edition.
Air travel data come from the model presented in:
Huang Z et al. An Open-Access Modeled Passenger Flow Matrix for the Global Air Network in 2010. PLoS One. 2013 May 15;8(5):e64317. doi: 10.1371/journal.pone.0064317.
which features an open-access passenger flow matrix for the global air network in 2010, later refined in to provide monthly estimates in:
Mao et al. Modeling monthly flows of global air travel passengers: An open-access data resource. Journal of Transport Geography. 2015 May;48. doi: 10.1016/j.jtrangeo.2015.08.017.
12.2 Heterogeneous Mixing
The \(\texttt{Heterogeneous}\) world factory groups agents together into households, and for each region there are two activities, \(\texttt{Home_Activity}\) and \(\texttt{Community_Activity}\). Individuals perform the \(\texttt{Home_Activity}\) in their assigned House, while they perform the \(\texttt{Community_Activity}\) in randomly selected grid squares, with the random selection being weighted by distance. Individuals above or below certain ages do not perform the \(\texttt{Community_Activity}\). Those who do perform the \(\texttt{Community_Activity}\) do so for 8 hours each weekday, between 8am and 4pm. When performing \(\texttt{Community_Activity}\), each individual gets a list of grid squares to choose from. The grid square containing their House is always included in this list.
The list of grid squares for each individual is obtained by sampling from a subset of all such squares in the region. This subset contains a number of squares nearest to their home square, in addition to a number of squares randomly sampled from all over the region. A small number of squares are randomly sampled from this set, weighted according to a simple gravity model. In particular, for an individual whose House is in square \(s_1\), the unnormalized weight \(w\) attached to a square \(s_2\) is given by the formula:
where \(N(s_2)\) is the number of people living in square \(s_2\), \(d\) is the Euclidean distance, and \(\gamma\) is the gravity model exponent.
Using the default reporter to render prevalence within each region, the \(\texttt{Heterogeneous}\) scenario can be visualized as follows:
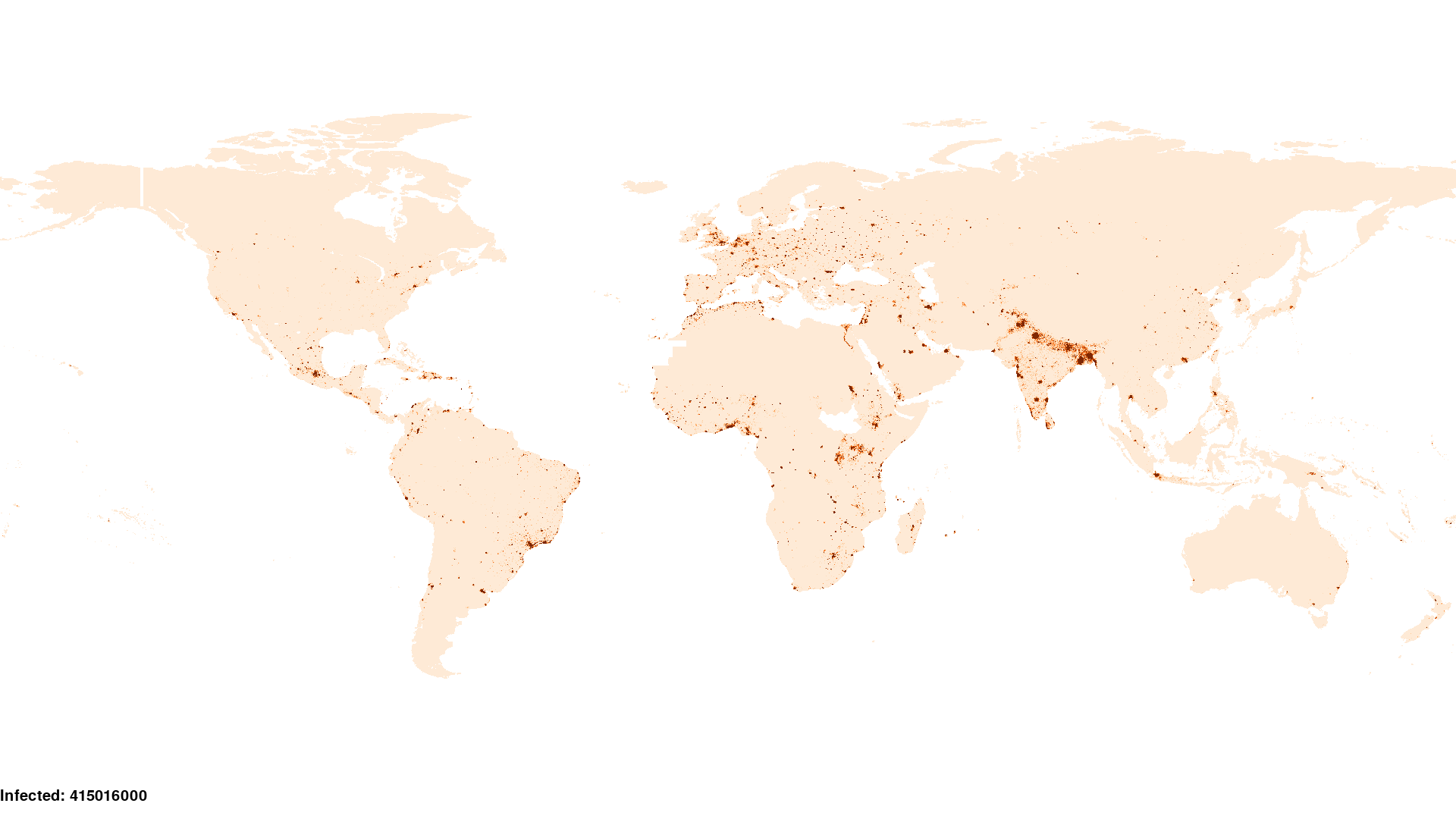
12.2.1 Input data
In addition to the datasets used for the \(\texttt{Homogeneous}\) scenario, the \(\texttt{Heterogeneous}\) scenario uses population grid data from NASA:
Center for International Earth Science Information Network - CIESIN - Columbia University. 2016. Gridded Population of the World, Version 4 (GPWv4): National Identifier Grid. Palisades, NY: NASA Socioeconomic Data and Applications Center (SEDAC). http://dx.doi.org/10.7927/H41V5BX1. Accessed 01 NOV 2022.
Data on household size come from the UN:
United Nations, Department of Economic and Social Affairs, Population Division (2022). Database on Household Size and Composition 2022. UN DESA/POP/2022/DC/NO. 8.
12.3 ABMlux
Pandemia is a far-reaching generalization of the earlier ABMlux model, used for the article:
Thompson J, Wattam S, Estimating the impact of interventions against COVID-19: From lockdown to vaccination. PLoS One. 2021 Dec 17;16(12):e0261330. doi: 10.1371/journal.pone.0261330.
In that article, the authors presented an agent-based model of the COVID-19 pandemic in Luxembourg, and used it simulate the impact of interventions over the first 6 months of the pandemic. The ABMlux code can be found here:
ABMlux brought together several datasets on the population in Luxembourg, describing households, places of work, care homes, schools, restaurants, shops and other locations, with over 2000 behavioural routines for agents defined on 10 minute time resolution using time use data. The ABMlux world factory outputs an abject which in the terminology of Pandemia would be called a region. This region features numerous activities and dozens of locations types. ABMlux allows this object to be saved as a \(\texttt{.abm}\) file, which can then be read by Pandemia’s \(\texttt{abmlux}\) world factory. This world factory converts the Luxembourg model into a Pandemia world object, on which a Pandemia simulation can then be built. To do this, first clone the repository
and install using pip install -e .[test] Then run the command
ms_abmlux Scenarios/Luxembourg/config.yaml sim_factory.abm
Once sim_factory.abm has been created, copy and paste this file into
Pandemia’s Scenarios/ABMlux/data folder.
While Pandemia regions are not required to have the complexity of the ABMlux region, such a level of detail is supported by Pandemia, and will generally produce the most realistic outputs, assuming such population data is available.
13 Validation
The validation of any individual-based epidemic model can be challenging, due to the computational burden of such models. Pandemia is fast, facilitating validation methods that require rapid iteration of the model. Such validation tools can be found in the codebase, although they are currently a work in progress.
14 Optimization
A common approach in epidemic modelling is to propose a small number of potential control strategies, before simulating each of them to determine which is most effective. Pandemia supports a more systematic approach, based on optimization algorithms.
Recall that the world and model components are specified using a Configuration. Given both a Configuration and a Policy, the simulation returns a Cost:
For a given Configuration, optimization algorithms can then be used to determine the Policy that minimizes the Cost. Recall that the Policy is the object referred to in Section 4, consisting of arrays of integers and floats, that determines which interventions are active or available in each region each day.
Such an optimization algorithm can be found in the Pandemia codebase. It uses a genetic algorithm to search for optimal policies. Much like the validation tools, this is also a work in progress.
Once these optimization algorithms are able to establish a mapping from a sample of configurations to a set of optimal policies, then methods from machine learning could be used to learn the remainder of this function.
Pandemia is able, via these optimization methods, to reveal potentially very effective control strategies that, due to the complexities of the system, may not be obvious to the modeller. Such strategies could save lives and reduce the cost of interventions. By inverting the cost function, Pandemia can also be used to determine which strategies are best avoided.